Transcoder
MPEG-2 data streams consist of a set of layers to define the video sequence.The sequence is composed of Groups of Pictures (GOP) that are one or more intra (I) frames and/or non-intra (P and/or B) frames.Intra Frames are coded with various compression techniques that are performed relative to information that is contained only within the current frame and not in any other frame in the video sequence.Non-intra frames rely on other frames in the sequence to achieve considerable more compression efficiency by taking advantage of temporal redundancies.P Frames predict frames from the frame immediately preceding it.B Frames predict frames from both the immediate preceding and following frames.B Frames require that the preceding frame be transmitted first, out of order, so that it can be calculated.The main advantage of B Frames is coding efficiency and errors generated will not be propagated further within the sequence.The disadvantage is that extra memory is required to store the 2 anchor frames used to calculate the B Frame.Whether intra or non-intra, each frame consists of several macroblocks.A continuous sequence of macroblocks form a slice.Each slice consists of macroblocks, which are 16x16 arrays of luminance picture elements with two 8x8 arrays of associated chrominance picture elements.The macroblocks can be further divided into 8x8 blocks.Each level described above has its own unique start code to describe the data to follow.
Before explaining how the decoder and encoder (mpeg2vidcodec_v12.tar.gz) manipulate this data in different ways, a brief explanation of each MPEG module needs to be explained.
- Discrete Cosine Transform (DCT) neighboring picture elements within an image tend to be highly correlated. DCT transforms them into fewer, more random elements. The transformation of an 8x8 block produces an 8x8 block of coefficients.
- Inverse Discrete Cosine Transform (IDCT) the DCT process is invertible. Its result can be used to regenerate the initial picture elements (with some error)
-
Quantization lower frequency DCT coefficients correspond to smoother
spatial patterns, while higher frequency DCT coefficients correspond to
finer special patterns. Since
the human eye is less sensitive to errors in high frequency than it is
for lower frequencies, the higher frequencies can be more coarsely quantized. The
quantization process divides each coefficient by a corresponding quantization
matrix value.
- Inverse Quantization (IQ) - multiplies DCT coefficients by a quantization matrix and quantization scale factor.
-
Motion Estimation consecutive frames tend to be similar except
for changes caused by objects moving within the frames. Motion
estimation attempts to adequately represent the changes or differences
between two frames. A
full search of the frame can produce the most accurate result, but it can
be very time inefficient. Less
exhaustive searches directly affect video quality. The
search tries to indicate how far horizontally and vertically the macroblock
must be moved to produce a match between frames.
-
Motion Compensation Uses the motion vectors created in motion
estimation to provide offset into past/future frames to form a prediction
error.
- Variable Length Coding (VLC) - a reversible procedure that assigns shorter codes to frequent events and longer codes to less frequent events.
- Variable Length Decoding (VLD) - reads every bit to find the unique code created above (VLC) to determine the event/content that follows.
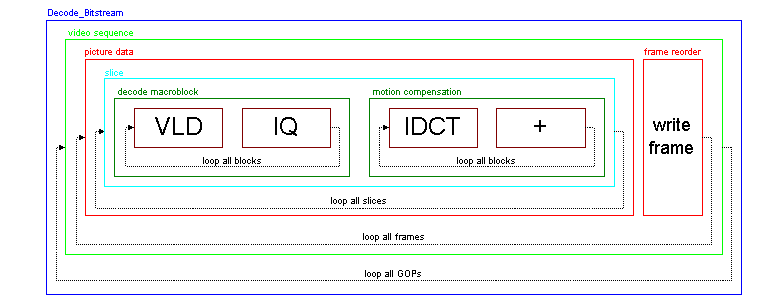
The decoder loops through all GOPs.Each
GOP loops through all of its frames.Each
frame loops through all of its slices.Each
slice loops through all of it macroblocks.When
all slices in a frame has been decoded, the decoded frame it written.
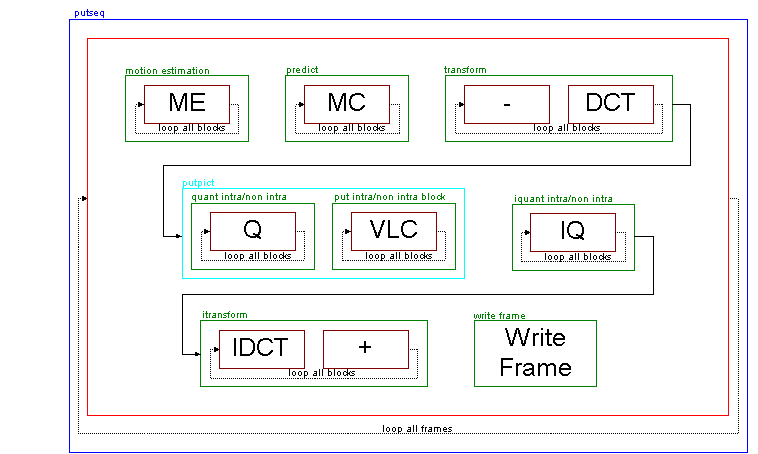
The encoder loops through all frames.For each frame, each macroblock is looped several times, one for each module in the encoder, then the encoded frame is encoded.
The transcoder integrates the encoder and decoder together.A frame that is decoded will be re-encoded.The re-encode process is done once the decoded frame is written.
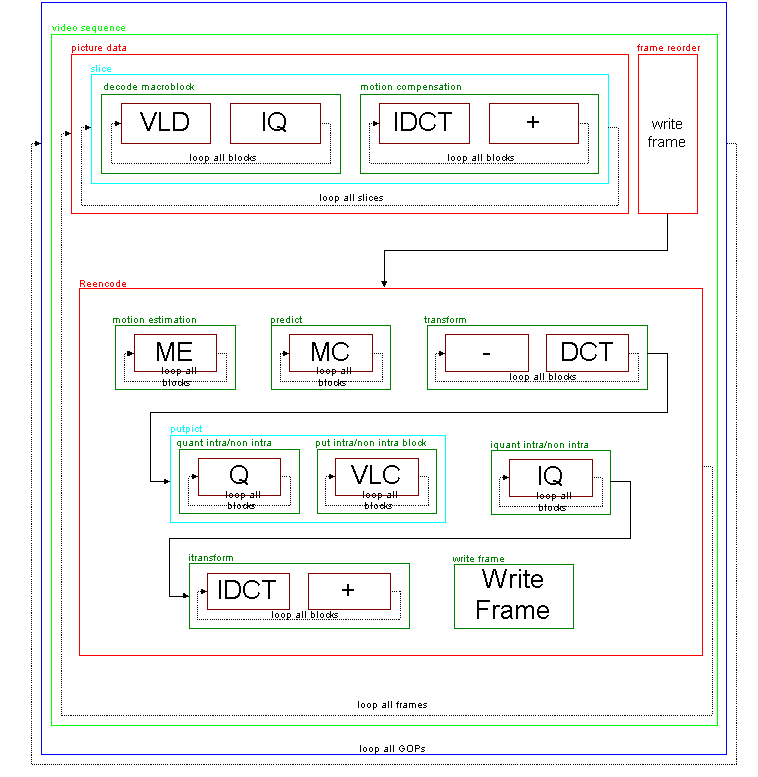
The re-encode process takes the putseq() function from the encoder and strips it down to a new function Reencode(int frame).Instead of looping all frames, the frame number to encode is passed in.Initialization routines from putseq() are inserted into the video_sequence() function.Since B Frames cause frames to be encoded out of order (display order), the frame to encode next will not be the frame just decoded.To accomplish this problem, determine the decoded frames display order (f).Determine if we already need a frame further into the video sequence (needed_frame).If the frame number we are currently decoding (ii) is the frame we have been waiting for (previous decodes where a future display order frame is needed), we can encode all previously decoded frames (all of which have had their display order frame decoded).
/*
calculate display order*/
ii
= Bitstream_Framenum -1;
if
(ii==0 || (ii-1)%M==0)
{
f
= (ii==0) ? 0 : ii+M-1;
if
(f>=nframes)
f
= nframes - 1;
}
else
f
= ii - 1;
/*
determine the highest display order frame needed*/
if
(f>= needed_frame)
needed_frame
= f;
/*
only encode frames which have been previously decoded*/
if
(ii>=needed_frame)
{
/*
now that we can encode this frame, encode any prior frames that have not*/
/*
been encoded, but have already been decoded (ie, catch up)*/
while
( last_encoded_frame < ii )
{
last_encoded_frame++;
Reencode(last_encoded_frame);
}
}
To calculate the percentage of time the transcoder occupies in each module, the start and end of each module had to be identified.Global variables were set up so that the duration of time taken in each module can be accumulated for all frames in the video sequence.The times are written out to a file so that they can be analyzed and graphed.For the samples included in the tar archive, durations for each module were combined for all streams and percentages of total time were calculated.
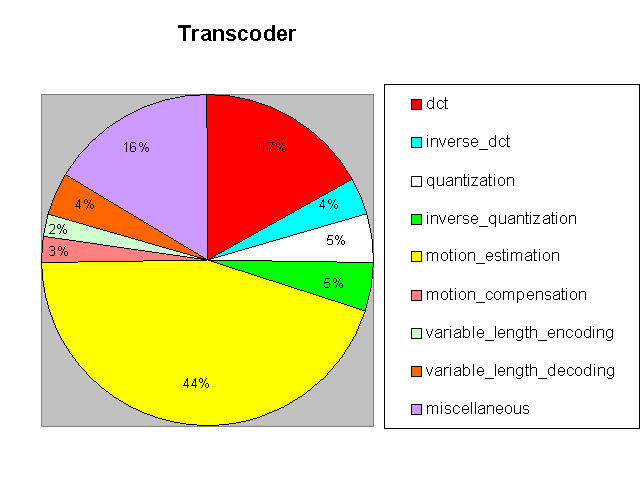
To calculate the duration times, the Unix gettimeofday() function is used.The function returns a structure containing the current seconds and microseconds. A call to gettimeofday() is issued at the start of the module and saved.Once the module has been completed, another call is issued and saved into another variable.The two structures are passed to the duration() function which converts the seconds (tv_sec) to microseconds (tv_usec) and returns the difference.
long
duration(struct timeval *tb, struct timeval *te)
{
return
(te->tv_sec-tb->tv_sec)*1000000+(te->tv_usec-tb->tv_usec);
}
After the last frame has been decoded and re-encoded, all the duration accumulators are concatenated and comma separated into a string which is written out to the duration.transcode (durationfile) file.
/*
format duration record and write to statistics file */
sprintf(msgtext,"%s,%d,%d,%d,%d,%d,%d,%d,%d,%d",argv[4],duration_dct,duration_idct,duration_quant,duration_iquant,
duration_motion_est,duration_motion_comp,duration_vlc,duration_vld,duration(&tb,&te));
duration_stats(msgtext);
/*
prints out the formated duration statistics record */
void
duration_stats(char* msg_text)
{
fprintf(durationfile,"%s\n",msg_text);
}
When combining the decoder and encoder there were several variable names that were common between the two sources.The only conflict was the decoders output types and the encoders input types.To eliminate the conflict, the decoders output types were renamed.Underscores were replaced with double underscores (ie, T_YUV replaced with T__YUV, etc.).
/*
encoder input types */
#define
T_Y_U_V 0
#define
T_YUV1
#define
T_PPM2
/*
decoder output types */
#define
T__YUV0
#define
T__SIF1
#define
T__TGA2
#define
T__PPM3
#define
T__X114
#define
T__X11HIQ 5
The input of the decoder and the input of the encoder were combined.The transcode script formats the required syntax as follows:
basename=`echo
$1 | cut -d\. -f1`
src/mpeg2transcode
-v0 -f -b $1 -o0 transcode%d $basename.par transcode.m2v
The encoded video stream is the only input parameter to the script.If the transcode%d is changed, it must also be changed in the .par file to match.If the o value is changed, it must also be changed in the .par file.The only values can be 0, for individual luminance and chrominance files (.Y, .U, .V), or a value of 3 for .PPM files.
There are two modifications that can still be made to improve this transcoder.First, remove the need for the .par file.Most of the values in the .par file can be read in from the decoded information.Several of the variables are already set because they share the same variable names (horizontal_size, vertical_size, etc.).There are still many variables that are structurally the same, but named differently (dc_prec, intra_dc_precision, etc.).There are variables that are structurally different (struct motion_data, int fcode[2][2]).There are still several variables that are not available in the decode process that are required in the .par file (N- number of frames in the video sequence, M distance between I and P frames, and several rate control values).These values can either become default values and/or remain in a scaled down .par file that can be used to override default values if set.It is not easy to just replace some of the values that are in common.color_primaries is one example of this.color_primaries is only set in the decoder if sequence extensions exists.The encoder checks color_primaries unconditionally.The source needs modified to check only if sequence extensions exist or to set default values.It will take a fair amount of time and recoding to eliminate the .par file entirely.
Another modification that needs to be made is to combine the IQ, IDCT, and motion vectors.Since the encoder and decoder were written in different programming styles, it will be tricky to reengineer the code (uses different variables, one uses arrays, the other strictly uses pointers).This will reduce the amount of time necessary to reencode a frame.It should make the transcoder much more efficient.