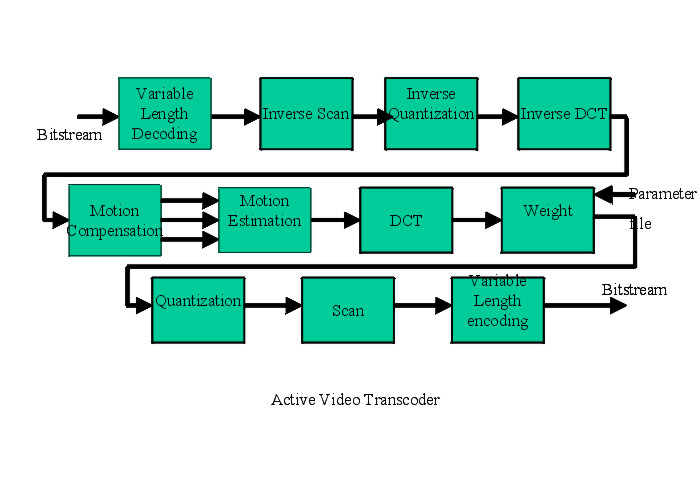
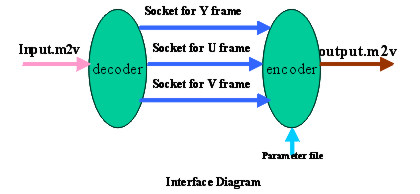
AVT: Active Video Transcoder SystemInternal Release Version 1.01 (DRAFT) Date: March, 2000 comments/bug report: perceptmedia@molokia.medianet.kent.edu We are developing the Active Video Transcoder (AVT) system that can perform full range of video transformation on an MPEG-2 video bit-stream system developed at the MEDIANET lab. The AVT can be dynamically installed and activated on network splice-points inside an Active Network. The AVT system can generate a new bit-stream matching the network characteristics and receiver requirement downstream.
[ What is AVT | Approach
| Coder Decoder | Transcoder
]
What is Active Video Transcoder system?In
the past years, the growth of backbone and periphery technology is pushing
up the upper limits of network speed. Here it seems that the diversity
in network capacity and the variability in the available quality of service
among different parts of the Internet is also rapidly increasing with it.In
deed the two most rapidly expanding area of the Internet is bandwidth limited.
Most projection indicates that it is the international front, which will
experience the most aggressive growth in the second decade of post-web
Internet. The other is the integration of the wireless networks. While
the mainstream networking research has focused on raving up the bandwidth,
however, very little focus has been paid to make system operable across
asymmetric network capacities, which is rapidly becoming a concern.
Video communication is one of the most demanding applications on the Internet. Todays video technology is ill suited to cope with variation. For example, in a video multicast distribution tree, if there are receivers with varying capacity, there are only three options. Either, the server will be serving at a high resolution version and low capacity receiver will be cut-off, or the server will serve with minimum version forcing the high-res client to be satisfied with the low-res version despite there local capacity. The third option is also not a good one, where the server has to serve multiple versions of the stream resulting in redundant information flow. We suggest optimum, and more intelligent result can be achieved, however it will require two fundamental innovations in the video and network technology. The first step is to develop a video transmission technology that can allow dynamic adaptation. The second is to find a new model of networking where such adaptive units can be implanted right inside the network splice points where the networks and links of varying characteristics meets in a global scale internet, a federation of networks with varying capacities and characteristics.Interestingly, video is just one of the first pressing application which requires such adaptation. Almost all the emerging network-based applications will require such adaptation ability. Approach:In
this research we are developing an Active network based trans-coder, which
can perform full transformation on an active junction point. Digital video
computations are massively computation intensive. In this two-part research
correspondingly, our goal is explore the current limits of technology and
at the same time propose viable models of in stream transcoding. In the
other part we are developing an Active Network node system, which will
use the Active Video Transcoder as an example, but will provide a means
for launching and maintenance of active Transcoder elements for other applications.
Our objective here is to find how seamlessly, large traducing systems can
be launched in a global Internet not only to absorb the variations of the
networked involved, but also withstanding the variations of the splice
nodes themselves. This document briefly describes the architecture of the
Active Video Transcoder (AVT) system.
Description of the Decoder and Encoder System:
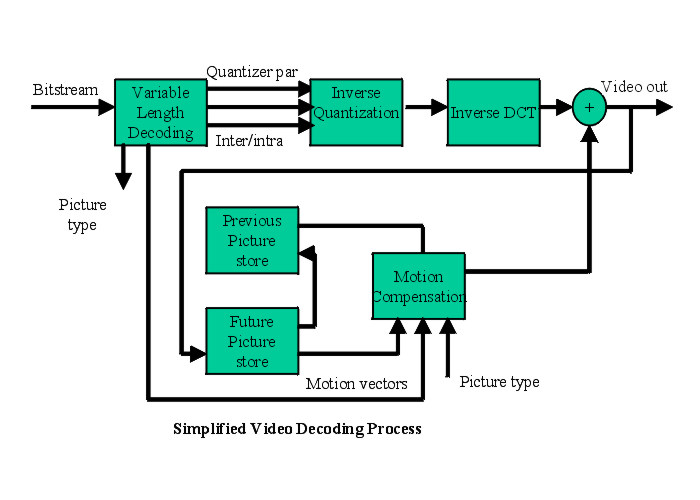
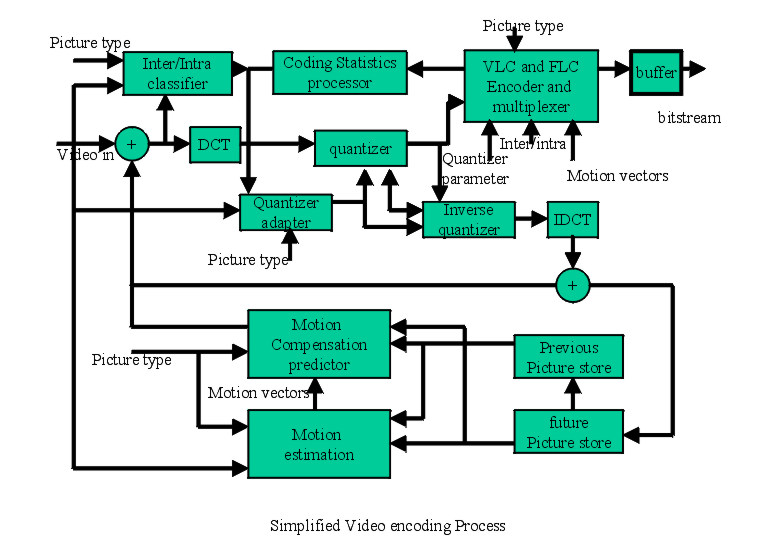
Fig-1 Modules:Below
we first describe the two principle modules inside: the decoder and the
encoder systems. The decoder reads an ISO/IEC 13818-2 stream. The processes
involved are: VLD (Variable Length Decoder), Inverse Quantization, Inverse
DCT computation. For P, and B frames it also includes a feedback loop,
where reference frames are looped through an inverse motion compensator.
The encoding process is reverse however, more complicated. For I pictures, it works only in forward loop, with DCT, quantization and variable length encoding. For P and B picture computation, frames are buffered, decoded and then subtracted from the current frame. During the macro-block wise subtraction, the best to subtract is searched by motion compensation process.
|